Abstract: Parallel computing can speed up our programme. From data parallel to process parallel, there are many parallel tool and way that we can use. The blog will introduce The Parallel Patterns Library (PPL), Open Multi-Processing (OpenMP) and Open Computing Language (OpenCL). Other important parallel tools such as CUDA and Hadoop will be introduced as topics in later blogs.
In general, there are four kinds of levels parallelism in computing, which are bit-level parallelism (BLP), instruction level parallelism (ILP), data level parallelism (DLP), and task level parallelism (more commonly Thread-level parallelism, short as TLP).
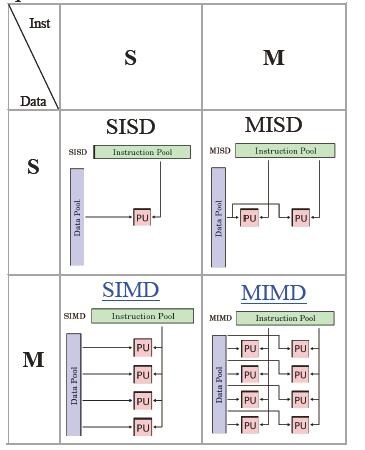
For data level parallelism, there are four kinds of modes for computer to perform parallel calculations. They are SISD, MISD, SIMD, and MIMD, and the meaning of them is illustrated as follows.
There are some tools to achieve the parallel computing, and the parallel scale ranges from multi-thread, multi-processe, multi-core to multi-computer. The follows are some rough classifications.
MPI
The MPI is a process level parallelism. MPI adopts distributed memory system and explicitly (data distribution method) realizes parallel execution. Message transmission is performed between processes. The scalability of MPI is good, but programming model is complicated.
Pthreads
Pthreads is a thread level parallelism. It uses shared memory system and is valid only on POSIX systems (linux, mac OS X, Solaris, HPUX, etc.). It is a library that can be connected to C programs. Currently, the standard C++ shared memory thread library is still under development. It may be more convenient to use this library in future to implement C++ programs.
OpenMP
OpenMP is a thread level parallelism. It uses shared-memory-distribution system and implicitly (data allocation) implements parallel execution with poor scalability. Hence OpenMP only applies to SMP (Symmetric Multi- Processing symmetric multi-processing architecture and DSM (Distributed Shared Memory) system, but not suitable for clustering.
OpenCL
OpenCL is a framework for heterogeneous platforms and can applied on CPU, GPU or other types of processors. OpenCL is a language (based on C99) for writing kernels (functions running on OpenCL devices) and consists of set of APIs for defining and controlling the platform. It provides parallel computing based on task partitioning and data segmentation. OpenCL is similar to the other two open industry standards, OpenGL and OpenAL, which are used for 3D graphics and computer audio, respectively.
CUDA
The GPU is designed to perform complex math and set calculations. There are many stream multiprocessor(SM) in a GPU, which are similar to CPU cores. CUDA is the usefull tool Launched by Nvidia to programm the GPU. The similarities and differences between OpenCL and CUDA:
- Differences:
- OpenCL is a general-purpose heterogeneous platform programming language that is cumbersome to take into account different devices.
- CUDA is a framework invented by nvidia specifically for programming on GPGPU. It is easy to use and easy to get started.
- Similarities:
- They are based on task parallelism and data parallelism.
Hadoop
Hadoop is a distributed system infrastructure developed by the Apache Foundation. Users can develop distributed programs without understanding the underlying details of the distributed architecture. Hadoop makes full use of the power of clusters for high-speed computing and storage.
1 PPL
The Parallel Patterns Library (PPL) provides algorithms that concurrently perform work on collections of data. These algorithms resemble those provided by the Standard Template Library (STL).
1.1 The parallel_for Algorithm
You can convert many for loops to use parallel_for. However, the parallel_for algorithm differs from the for statement in the following ways:
The
parallel_foralgorithm does not execute the tasks in a pre-determined order.The
parallel_foralgorithm does not support arbitrary termination conditions. The parallel_for algorithm stops when the current value of the iteration variable is one less than last.The
_Index_typetype parameter must be an integral type. This integral type can be signed or unsigned.The loop iteration must be forward. The
parallel_foralgorithm throws an exception of typestd::invalid_argumentif the_Stepparameter is less than 1.The exception-handling mechanism for the
parallel_foralgorithm differs from that of a for loop. If multiple exceptions occur simultaneously in a parallel loop body, the runtime propagates only one of the exceptions to the thread that calledparallel_for. In addition, when one loop iteration throws an exception, the runtime does not immediately stop the overall loop. Instead, the loop is placed in the cancelled state and the runtime discards any tasks that have not yet started.
1.2 The parallel_for_each Algorithm
The parallel_for_each algorithm resembles the STL std::for_each algorithm, except that the parallel_for_each algorithm executes the tasks concurrently. Like other parallel algorithms, parallel_for_each does not execute the tasks in a specific order.
1.3 The parallel_invoke Algorithm
The concurrency::parallel_invoke algorithm executes a set of tasks in parallel. It does not return until each task finishes. This algorithm is useful when you have several independent tasks that you want to execute at the same time.
1.4 The parallel_transform Algorithm
You can use the parallel transform algorithm to perform many data parallelization operations. For example, you can:
- Adjust the brightness of an image, and perform other image processing operations.
- Sum or take the dot product between two vectors, and perform other numeric calculations on vectors.
- Perform 3-D ray tracing, where each iteration refers to one pixel that must be rendered.
Important: The iterator that you supply for the output of
parallel_transformmust completely overlap the input iterator or not overlap at all. The behavior of this algorithm is unspecified if the input and output iterators partially overlap.
1.5 The parallel_reduce Algorithms
The parallel_reduce algorithm is useful when you have a sequence of operations that satisfy the associative property. Here are some of the operations that you can perform with parallel_reduce:
- Multiply sequences of matrices to produce a matrix.
- Multiply a vector by a sequence of matrices to produce a vector.
- Compute the length of a sequence of strings.
- Combine a list of elements, such as strings, into one element.
1.6 Code Example for PPL Algorithms
Here is the code example for above algorithms.
Please add header #include <ppl.h>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
struct my_data
{
int num;
std::string note;
};
// Returns the result of adding a value to itself.
template <typename T>
T twice(const T& t)
{
return t + t;
}
//Test Parallel_for algorithm
void test_Parallel_for()
{
concurrency::parallel_for(1, 6, [](int value) {
std::wstringstream ss;
ss << value << L' ';
std::wcout << ss.str();
});
}
//Test Parallel_for_each algorithm: regular
void test_Parallel_for_each1()
{
std::vector<std::string> my_str = { "hi", "world", "hello", "c", "language"};
concurrency::parallel_for_each(begin(my_str), end(my_str), [](std::string value) {
std::cout << value<<std::endl;
});
}
//Test Parallel_for_each algorithm: wrong use, data should be independent
void test_Parallel_for_each2()
{
std::vector<std::string> my_str = { "hi", "world", "hello", "c", "language" };
int mark = 100;
concurrency::parallel_for_each(begin(my_str), end(my_str), [&mark](std::string value) {
std::cout << value <<" "<<mark<< std::endl;
});
}
//Test Parallel_for_each algorithm: test class data parallel
void test_Parallel_for_each3()
{
my_data data1 = { 100,"hi" };
my_data data2 = { 200,"world" };
my_data data3 = { 300,"language" };
std::vector<my_data> my_str = { data1,data2,data3 };
concurrency::parallel_for_each(begin(my_str), end(my_str), [](my_data value) {
std::cout << value.num << " " <<value.note << std::endl;
});
}
//Test Parallel_invoke algorithm
void test_Parallel_invoke()
{
int n = 54;
double d = 5.6;
std::wstring s = L"Hello";
concurrency::parallel_invoke(
[&n] { n = twice(n); },
[&d] { d = twice(d); },
[&s] { s = twice(s);}
);
std::wcout << n <<" "<< d<<" "<<s<<std::endl;
}
//Test Parallel_transform algorithm
void test_Parallel_transform()
{
std::vector<int> values(1250000);
std::generate(begin(values), end(values), std::mt19937(42));
std::vector<int> results(values.size());
std::vector<int> results2(values.size());
// Negate each element in parallel.
concurrency::parallel_transform(begin(values), end(values), begin(results), [](int n) {
return -n;
});
// Alternatively, use the negate class to perform the operation.
concurrency::parallel_transform(begin(values), end(values),
begin(results), std::negate<int>());
// Demonstrate use of parallel_transform together with a binary function.
// This example uses a lambda expression.
concurrency::parallel_transform(begin(values), end(values), begin(results),
begin(results2), [](int n, int m) {
return n - m;
});
// Alternatively, use the multiplies class:
concurrency::parallel_transform(begin(values), end(values), begin(results),
begin(results2), std::multiplies<int>());
}
//Test Parallel_reduce algorithm
void test_Parallel_reduce()
{
std::vector<std::wstring> words;
words.push_back(L"Hello ");
words.push_back(L"i ");
words.push_back(L"like ");
words.push_back(L"c ");
words.push_back(L"language, ");
words.push_back(L"and ");
words.push_back(L"parallel ");
words.push_back(L"programming.");
// Reduce the vector to one string in parallel.
std::wcout << concurrency::parallel_reduce(begin(words), end(words), std::wstring()) << std::endl;
}
int main()
{
// Alternatively, use one of following test function
//test_Parallel_for();
//test_Parallel_for_each1();
//test_Parallel_for_each2();
//test_Parallel_for_each3();
//test_Parallel_invoke();
//test_Parallel_transform();
test_Parallel_reduce();
return 0;
}
2 OpenMP
The basic format of Compiler Directive(#pragma omp) is as follows:1
Among them, “[]” indicates optional, and each Compiler Directive acts on the followed statement (the bracketed portion of “{}” in C++ is a compound statement).
Directive-name can be: parallel, for, sections, single, atomic, barrier, critical, flush, master, ordered, threadprivate (11 in total, only the first 4 have optional clauses).
The clause (sentence) is equivalent to the modification of Directive, which defines some parameters of Directive. The clause can be: copyin(variable-list), copyprivate(variable-list), default(shared | none), firstprivate(variable-list), if(expression), lastprivate(variable-list), nowait, num_threads(num) , ordered, private(variable-list), reduction(operation: variable-list), schedule(type[,size]), shared(variable-list) (13 total).
For example, #pragma omp parallel means that the subsequent statements will be executed in parallel by multiple threads, and the number of threads is preset by the system (generally equal to the number of logical processors, for example, i5 4 cores and 8 threaded CPUs have 8 logical processors). Optional clauses can be added to the directive. For example, #pragma omp parallel num_threads(4) still means that subsequent statements will be executed in parallel by multiple threads, but the number of threads is 4.
2.1 parallel
parallel indicates that the subsequent statement will be executed in parallel by multiple threads, which is already known. The statement (or block of statements) after #pragma omp parallel is called a parallel region.
You can use num_threads clause to change the default number of threads.
2.2 for
for directive divides multiple iterations of the for loop into multiple threads, that is, the iterations performed by each thread are not repeated, and the iterations of all threads are exactly all the iterations of the C++ for loop. Here the C++ for loop requires some restrictions so that you can determine the number of loops before executing, for example, C++ for should not contain breaks.
2.3 section
The section directive is used for task parallelism, which indicates that the following code block contains a section block that will be executed in parallel by multiple threads.
2.4 critical
When one line of code is executed by one thread, other threads cannot execute (the line of code is critical).
2.5 Code Example for OpenMP Algorithms
Here is the code example for above algorithms.
Please add header #include<omp.h>
Important: Please turn on the OpenMP in configuration
Property~C/C++~Language~OpenMP Support~Yes
1 |
|
3 OpenCL
The main design goal of OpenCL is to provide a parallel computing platform that is suitable for a variety of different devices. However, the universal property is the sacrifice of convenience, so OpenCL programming is very tedious. So here, only an example of adding two numbers is provided for demonstration.
The following is the code example for OpenCL programming.
For environment configuration:
- Add header
#include <CL/cl.h> - The header file and library file can be found in CUDA tool kit, so add the additional include directory as follows(my configuration, you can look for your tool kit path):
Property~C/C++~Regular~additional include directory~D:\NVIDIA\CUDA\CUDAToolkit\includeProperty~Linker~Regular~additional library directory~D:\NVIDIA\CUDA\CUDAToolkit\lib\x64Property~Linker~Import~additional dependencies~OpenCL.lib
1 |
|
The kernel file is Add.cl is
1 | __kernel void add_kernel(__global const float *a, __global const float *b, __global float *result) |
The all code files can be found in my Github