Abstract: This blog post offers a exploration of the 2017 paper “Attention Is All You Need” by Ashish Vaswani and colleagues at Google, introducing the Transformer architecture that replaces recurrent networks with self-attention mechanisms for sequence transduction tasks like machine translation. It explains the core principles, including scaled dot-product and multi-head attention; the encoder-decoder structure with positional encodings, residual connections, and layer normalization; and implementation details such as training optimizations, emphasizing the model’s parallelizability and efficiency.
这篇论文一出就颠覆了序列建模的世界,Transformer架构到现在还是各种大模型的基石。它像个优雅的简化版工具箱,把RNN的复杂性扔掉,全靠注意力机制(attention)来捕捉依赖关系。
背景:序列任务的痛点和灵感来源
简单说,序列任务比如机器翻译,就是把输入序列(源语言句子)转成输出序列(目标语言)。传统方法多用RNN(循环神经网络)或LSTM,编码器(encoder)先处理输入成隐藏状态,解码器(decoder)再一步步生成输出。这种方式有两大问题:
- 顺序计算的瓶颈:RNN是串行的,一个时间步要等上一个算完,长序列时训练慢,GPU并行不开。
- 远距离依赖难抓:越远的词间关系,信息越容易丢(梯度消失)。
注意力机制的出现缓解了后一个问题,它让模型能“看”整个序列,动态加权相关部分。但之前,注意力还是RNN的配角。作者们想,能不能扔掉RNN,全用注意力?灵感来自自注意力(self-attention),它能直接在序列内部建模依赖,不分距离。Transformer就这样诞生了:纯注意力架构,编码器-解码器结构,但全并行化,训练只需12小时在8个GPU上,就能赶超当时SOTA。
核心思想:注意力机制的数学原理
Transformer的灵魂是注意力。简单说,注意力就像个智能加权平均:给定查询(query),从一堆键-值对(key-value)中挑出相关的,计算加权输出。
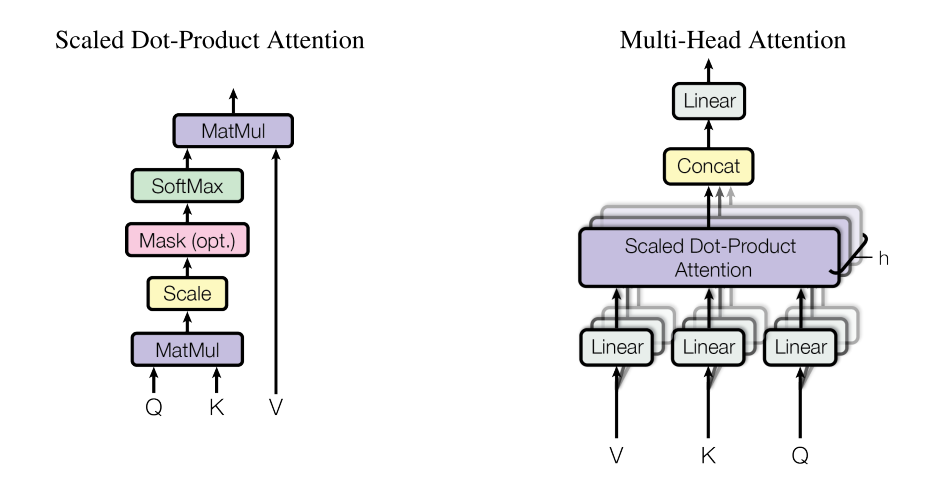
- Scaled Dot-Product Attention(核心计算单元):
假设输入是序列X,投影成Q(查询)、K(键)、V(值),每个$d_k$维。注意力分数是Q和K的点积(dot product),除以$sqrt(d_k)$防梯度爆炸,再softmax成权重,最后乘V求和。公式:为什么缩放?点积太大,softmax就扁平化,梯度小。
这步捕捉全局依赖:每个位置都能“看到”所有位置,操作数是常数级(不像CNN随距离线性增长)。 - Multi-Head Attention(多头注意力):
单头注意力可能只抓一种关系(比如语法或语义)。作者用h=8个头,并行计算每个头的注意力(投影到$d_{model}/h$维),再concat并线性变换。好处:多视角捕捉依赖,丰富表示。公式上,就是h个注意力并行,输出为什么有效?实验显示,多头能补偿单头的分辨率损失(平均化导致的模糊)。 - 自注意力 vs. 编码器-解码器注意力:
编码器用自注意力(Q=K=V来自输入)。解码器自注意力加掩码(mask),防未来信息泄露(生成时只能看已生成部分)。解码器还加编码器-解码器注意力:Q从解码器,K=V从编码器输出,帮输出对齐输入。
整个机制端到端可微,纯前馈计算,无循环。
模型结构:Encoder-Decoder的堆叠
Transformer是经典的编码器-解码器,但每个部分是N=6个相同层的堆叠(如下图)。输入先加位置编码(positional encoding),因为注意力无序。
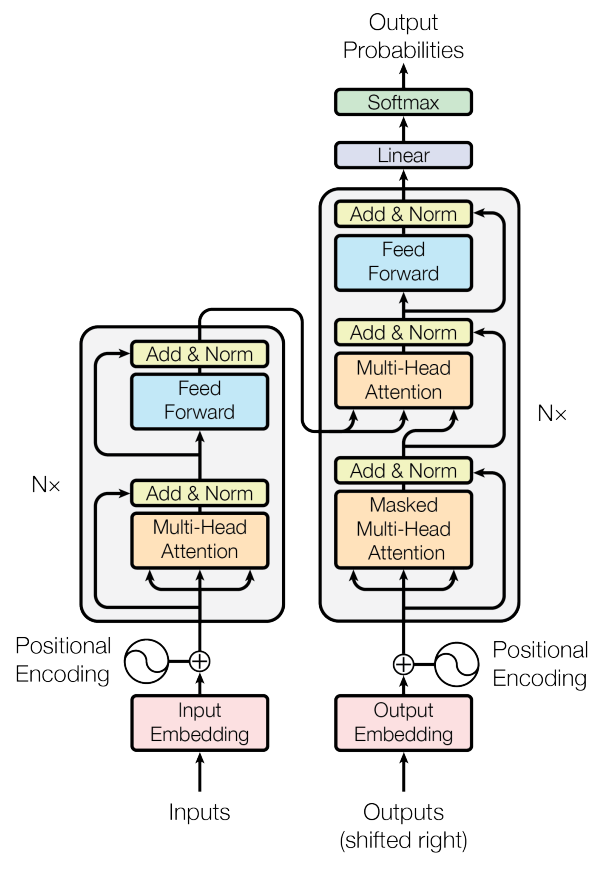
- 位置编码:用sin/cos函数编码位置,波长从2π到10000π,公式,偶数cos。为什么?固定、无参,能外推长序列(不像学习的位置嵌入)。
- 编码器(Encoder):6层,每层两个子层:
- Multi-Head Self-Attention:捕捉输入间依赖。
- Position-wise Feed-Forward:全连接层,,两层ReLU,$d_{ff}=2048$。
每个子层后加残差连接(),稳定训练。
- 解码器(Decoder):也6层,但每层三个子层:
- Masked Multi-Head Self-Attention:自注意力,掩码未来。
- Multi-Head Attention over Encoder:Q从解码器,K/V从编码器。
- Position-wise Feed-Forward。
同样残差+LayerNorm。输出嵌入偏移一位,确保自回归。
整体:输入嵌入$d_{model}=512$,序列长最多能并行。解码器生成时,逐位预测下一个词(softmax过vocabulary)。
实现细节:怎么让它跑得稳
作者没发明新trick,全是工程优化:
- 残差和LayerNorm:每子层后加,防梯度爆炸/消失。LayerNorm在特征维标准化。
- Dropout:子层输出和注意力权重后加0.1 dropout。
- 训练:Adam优化,warmup 4000步后lr衰减。标签平滑(label smoothing)防过拟合。
- 并行化:无RNN,batch内全并行,序列长时优势大。
- 变体:论文提了base()和big模型,tensor2tensor代码库加速实验。
实现上,作者强调Transformer泛化好:不只翻译,还能解析树(constituency parsing),数据少时也行。
感想
这篇论文就像场革命:扔掉RNN的包袱,用注意力简化一切,却更强大。原理上,它把序列依赖抽象成矩阵运算,结构上模块化易扩展(BERT、GPT都继承了)。