Abstract: This blog post offers an overview of the 2019 paper “PointPillars: Fast Encoders for Object Detection from Point Clouds” by Alex H. Lang and colleagues, presenting a pillar-based encoder that learns features from vertical columns of LiDAR points using simplified PointNets, enabling efficient 2D convolutional detection. It covers the principles of converting sparse point clouds into a dense pseudo-image via pillar feature encoding (with point decorations); the 2D backbone with top-down and upsampling paths; the SSD detection head for oriented 3D boxes; key implementation details including data augmentation and loss design; and experimental results on KITTI, achieving state-of-the-art BEV and 3D performance at 62 Hz (up to 105 Hz), significantly outperforming prior methods in both speed and accuracy.
这篇工作把点云转成“柱子”(pillars)来学特征,然后用2D卷积做检测。论文提出了一种简单高效的编码器PointPillars,在KITTI基准上,纯LiDAR就打败很多融合方法,速度达到62Hz(更快版105Hz)。它平衡了速度和精度,避开了3D卷积的慢和手工特征的局限。现在很多检测框架还在参考它的思路。
背景和动机:点云检测的效率难题
自动驾驶里,LiDAR点云是核心传感器,能给精确3D信息。但点云稀疏、无序、3D,怎么高效转成检测友好的格式是个老问题。早期方法用固定手工特征(如按网格统计高度、密度),快但精度一般。后来VoxelNet用PointNet学体素特征,再3D卷积,精度高但慢(4.4Hz)。SECOND改进后到20Hz,但3D卷积还是瓶颈。
作者观察到,鸟瞰(BEV)视角下,垂直方向信息有限,不需要精细体素划分。于是提出“柱子”(pillars):垂直柱子学特征,水平用2D CNN。动机很简单——追求实时(real-time)部署,又不牺牲太多精度。
核心原理:Pillar编码 + 端到端学习
PointPillars原理是“柱状特征学习”。把点云按x-y平面均匀划分成柱子(像垂直柱),每个柱子里的点用简化PointNet学特征,然后散射回伪图像(pseudo-image),后续全2D处理。
- 为什么柱子? 柱子天然对齐BEV,避免z方向手工调bin。学特征比固定编码(如高度直方图)更灵活,能捕捉点分布、反射率等丰富信息。
- 端到端:从原始点云到3D框,全可微。避免多阶段误差累积。
- 效率:所有操作转2D卷积,GPU友好。稀疏柱子(大多空)用掩码处理,进一步提速。
整体像把3D问题“压扁”成2D,保留必要信息。
模型结构:编码器 + 骨干 + 检测头
结构清晰三部分(如下图):
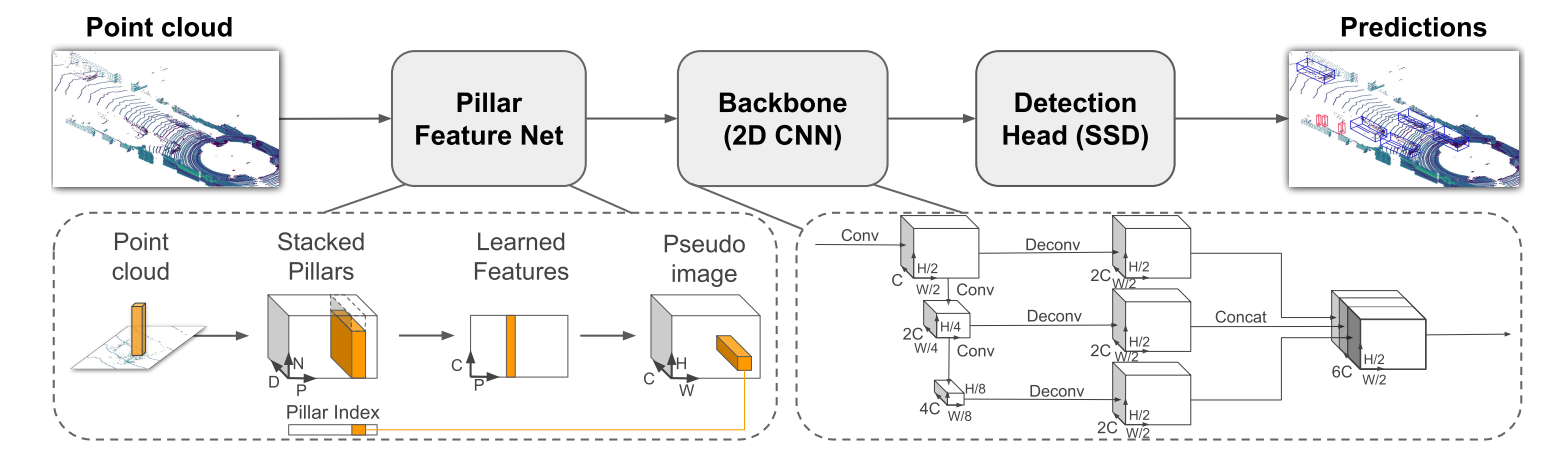
- Pillar Feature Net(编码器):
- 输入点云,按分辨率(如0.16m)分柱子。
- 每个点扩9维:原始(x,y,z,r) + 柱均值偏移$(x_c,y_c,z_c)$ + 柱中心偏移$(x_p,y_p)$。
- 简化PointNet:线性层+BN+ReLU,每点得特征,然后max-pool得柱特征。
- 散射回伪图像$(C x H x W)$,稀疏变密集伪图。
- Backbone(2D CNN):类似VoxelNet,但全2D。
- Top-down:多Block(stride递增,通道递增),提取多尺度。
- Upsample + concat:融合不同分辨率特征。
- 输出高维特征图。
- Detection Head:SSD单阶段头。
- 锚框回归3D框(x,y,z,w,l,h,θ)。
- Focal loss分类,Smooth L1回归,方向softmax辅助朝向。
整个网络轻量,车类和行人/骑行者可共享骨干(stride略调)。
实现细节:工程优化和训练
实现基于PyTorch,后用TensorRT加速。
- 数据:KITTI,训练时只用投影到图像的点(模拟真实)。
- 增强:地面真值采样(database)+ 每框扰动(小旋转平移)+ 全局翻转/旋转/缩放/平移。作者发现少量增强对行人更好。
- 锚框和匹配:2D IoU匹配,z和高单独回归。
- 损失:SECOND风格,定位+分类+方向。
- 训练:Adam,160 epoch,学习率衰减。Batch小(2-4)。
- 推理:NMS(轴对齐,0.5 IoU)。
- 变体:不同分辨率调速度/精度(0.12²到0.28²)。
细节上,柱子数限12000/样本,点/柱限100,零填充或采样。装饰点特征是提升关键。
实验部分:速度精度双赢
在KITTI val/test全面测。
- BEV/3D:车Easy/Mod/Hard mAP超SECOND、VoxelNet等,行人和骑行者也领先融合方法。AOS(朝向)68.86%,领先。
- 速度:62Hz(TensorRT),匹配SOTA精度;调分辨率到105Hz,仍接近顶尖。
- 定性:可视化紧框,失败多在远/遮挡或混淆(行人/杆子、骑行者/桌子)。
- 消融:
- 分辨率:大柱子快,精度略降(行人/骑行者敏感)。
- 编码:学特征大幅优固定编码,尤其大柱子。
- 装饰/增强:xp/yp +0.5 mAP,数据库采样稳。
- 骨干瘦身:通道减半仍强,加速明显。
实验证明:Pillar编码高效,2D全流程实时,学特征胜手工。
感想
PointPillars的框架简单实用——柱子学特征 + 2D骨干,避3D卷积坑,端到端学丰富表示。比VoxelNet快很多,还不输精度,现在很多BEV检测还在用类似思路。局限是稀疏场景下小物体稍弱,但整体性价比高。