Abstract: This blog post offers an overview of the 2020 paper “End-to-End Object Detection with Transformers” by Nicolas Carion and colleagues at Facebook AI, reimagining object detection as a direct set prediction task to eliminate hand-crafted components like anchors or NMS. It explains the core principles of bipartite matching loss for unique assignments and Transformer-based relational modeling; the CNN-backbone plus encoder-decoder structure with learned object queries; implementation details such as training schedules, positional encodings, and extensions to panoptic segmentation; and key experimental insights on COCO, including competitive AP with Faster R-CNN, stronger large-object performance, and ablation studies highlighting the matching loss’s importance.
这篇论文把检测问题当成直接的集合预测,扔掉了一堆手工设计的东西,像NMS或anchor box。在COCO基准上和Faster R-CNN打平,还能轻松扩展到全景分割。为什么值得聊?因为它开启了Transformer在检测领域的先河,现在像DETR的变体到处是。
背景和动机
传统物体检测像Faster R-CNN或YOLO,都间接处理:先生成一堆提案(proposals)或锚框(anchors),再回归框和分类。这引入了很多先验知识,比如锚框设计、NMS去重叠,影响性能还难调。论文想简化:直接把检测当成集合预测问题——输入图像,输出固定数量的框和标签集合,无需中间步骤。
动机来自NLP的Transformer成功:端到端序列预测。视觉里,自注意力能全局建模对象关系,但之前尝试(如RNN-based)加了更多先验,没在COCO上赢强基线。DETR用Transformer encoder-decoder,直接并行输出所有预测,结合二分匹配损失确保唯一性。简单说,就是让模型自己学全局上下文,避开手工规则。
核心原理:集合损失 + Transformer关系建模
DETR的原理是把检测视为直接集合预测,关键两部分:损失函数和Transformer。
- 二分匹配损失(Bipartite Matching Loss):传统检测用锚框匹配目标,但DETR用匈牙利算法(Hungarian)匹配预测和真值集合。预测固定N个(N>对象数),多余的标“no object”(∅)。匹配考虑框位置、类别,损失是匹配对的L1框损失 + 交叉熵类损失 + GIoU。为什么?确保预测无序、唯一,端到端训练。
- Transformer建模:用自注意力捕捉对象间和全局图像关系。编码器处理CNN特征,解码器用对象查询(object queries)——学到的固定向量,像问“这里有什么对象?”。注意力让查询全局attend特征,建关系(如对象不重叠)。
原理上,DETR去手工先验,靠数据和注意力学隐式规则。并行输出避开自回归的顺序依赖。
模型结构:CNN + Transformer Encoder-Decoder
结构直观:CNN backbone + Transformer encoder-decoder + 预测头。如下图。
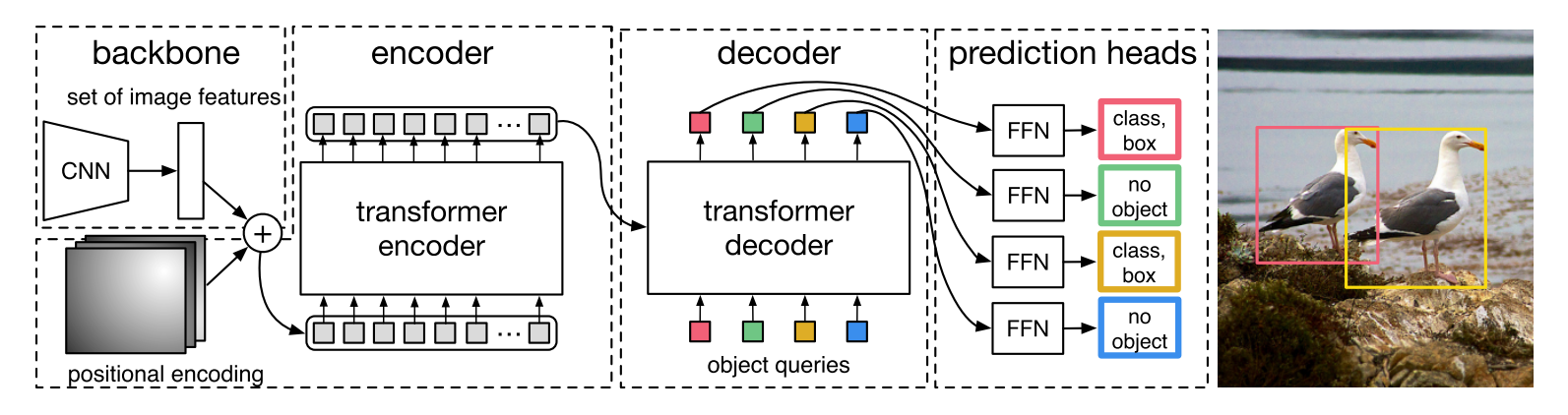
- CNN Backbone:ResNet提取特征,扁平成序列($H/32 × W/32 × D$)。
- Transformer Encoder:标准,多头自注意力 + FFN,处理特征序列,加位置编码(sin/cos)编码空间。
- Transformer Decoder:也标准,但查询是N个学到的object queries。每个解码层:自注意力(查询间),交叉注意力(查询attend编码器输出),FFN。输出N个嵌入。
- 预测头:简单FFN,从嵌入预测框(cx,cy,h,w归一化)和类(包括∅)。
N固定(如100),解码并行,非自回归。整体端到端,无自定义层,用标准库实现。
实现细节:训练调优
实现简单,用PyTorch标准Transformer和ResNet。超参:N=100,查询随机初始化。训练:AdamW,300epoch,COCO上warmup+衰减。aug如随机裁剪。推理:直接输出,过滤∅类,无NMS。
细节上,位置编码重要(2D sin/cos)。损失权重:类2,L1框5,GIoU2。扩展全景分割:加mask头,损失加Dice/Focal。
实验部分
第4节实验在COCO上对比Faster R-CNN(带FPN)。DETR-DC5(ResNet-50)AP 42.0,和Faster R-CNN-FPN 42.0平,但大物体AP_L 63.1(Faster 61.1),小物体弱(AP_S 23.7 vs 27.3)。为什么?全局注意力利于大物体上下文,但小物体需更好多尺度。
训练长:300epoch(Faster 37.5),但端到端。消融:去匹配损失AP掉10+;Transformer层深好(6层最佳)。全景分割:DETR超Panoptic FPN +3 PQ。
这些点显示DETR概念验证成功,但小物体和速度(23 FPS vs Faster 42)有改进空间。
小结
DETR的框架是CNN+Transformer+匹配损失,思想是端到端集合预测,简化管道,它启发了ViT-DETR等。