Abstract: This blog post offers an overview of the NVIDIA paper “Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail,” presenting a vision-language-action (VLA) model that integrates structured Chain of Causation (CoC) reasoning with trajectory planning to address long-tail safety-critical scenarios. It details the principles of causally grounded reasoning aligned with driving decisions; the modular architecture built on Cosmos-Reason backbone with efficient multi-camera tokenization and a diffusion-based action expert for real-time feasible trajectories; the hybrid CoC dataset construction via human-in-the-loop and auto-labeling; and the multi-stage training combining supervised fine-tuning for reasoning elicitation with GRPO-based RL post-training to optimize reasoning quality, reasoning-action consistency, and trajectory performance. Experiments demonstrate notable gains in planning accuracy and collision reduction in both open-loop and closed-loop settings, highlighting a practical path toward interpretable and robust Level 4 autonomy.
先是看到了alpamayo1.5的论文,开源在 https://github.com/NVlabs/alpamayo1.5 ,然后顺便看下Alpamayo-R1的论文,思路是让端到端自动驾驶“会思考”。他们在Alpamayo-VA基础上,加入了结构化的因果推理(Chain of Causation),让模型不只预测轨迹,还能解释“为什么这么开”。这对长尾场景特别有用,因为纯模仿学习在稀有危险情况里容易翻车。
框架思路很清晰:用VLA(Vision-Language-Action)把视觉、语言推理和动作预测统一起来,再通过强化学习对齐推理和实际行为。不是空谈可解释性,而是真正让推理帮助规划更安全。
背景和动机:端到端需要“思考”能力
端到端(E2E)自动驾驶近年发展很快,大模型+大数据让性能不断提升,但作者指出一个核心痛点:在长尾、安全关键场景里,监督信号稀疏,模型缺乏因果理解,容易出问题。传统模块化系统有明确推理步骤,但端到端往往黑箱,直接从传感器到控制,泛化差。
LLM的Chain-of-Thought(CoT)启发了他们:推理能让模型在语言空间探索多种可能,再落地到动作。但驾驶场景不能纯文本自由推理,需要因果接地(causally grounded),把观察到的证据和具体驾驶决策连起来。Alpamayo-R1的目标就是搭建这种“推理-动作”桥梁,提升长尾鲁棒性,同时保持实时性。
核心原理:结构化因果推理 + VLA统一建模
论文的核心是规划导向的推理:推理不是装饰,而是功能组件,直接服务动作预测。
- Chain of Causation (CoC):结构化推理痕迹。每个痕迹包含:观察到的关键因素(critical components,如前方车辆、红灯、车道线)→ 明确驾驶决策(纵向/横向,如跟车、让行、变道)→ 自然语言因果链。避免模糊描述(如“小心点”)和未来信息泄露,确保只用历史可观察证据。
- VLA框架:视觉(多相机)→ 语言推理(Cosmos-Reason骨干)→ 动作(扩散解码器生成轨迹)。推理输出作为条件,指导轨迹生成,实现“先想后动”。
- 对齐机制:用RL确保推理质量和推理-动作一致性。模型不能说一套做一套。
原理上,这让模型从“模仿专家轨迹”升级到“理解为什么这么做”,提升泛化和安全性。
模型结构:模块化VLA设计
AR1是模块化的,便于扩展(下图):
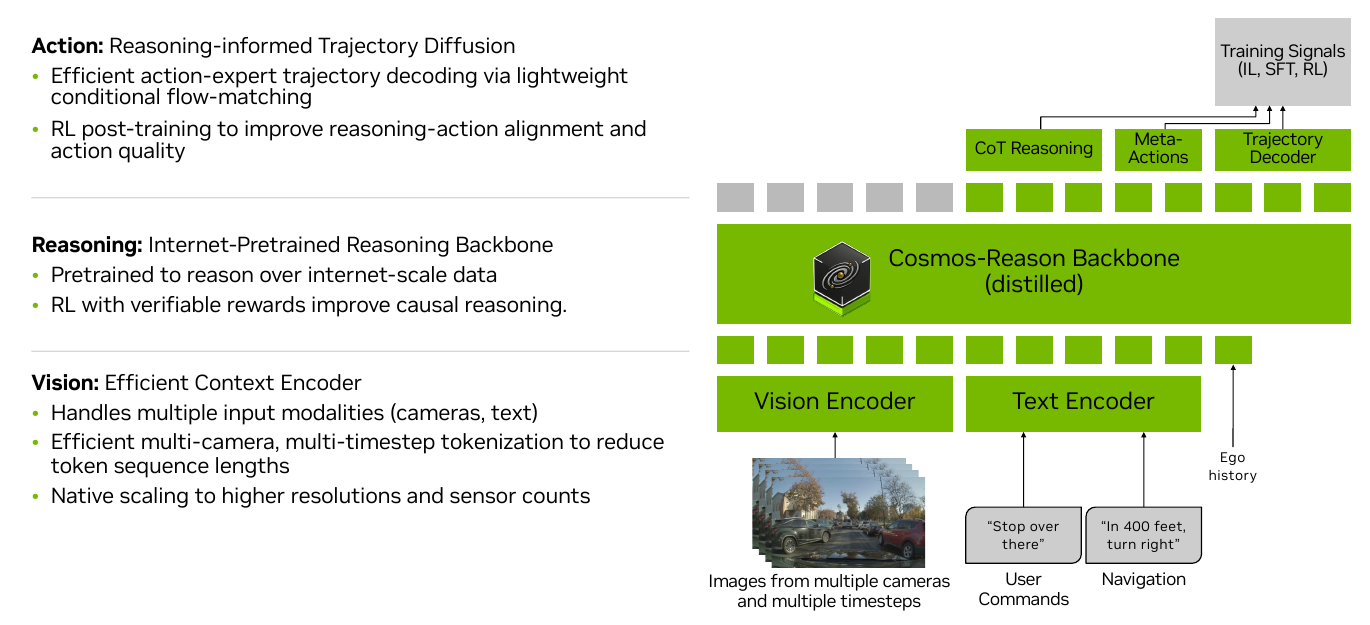
- 视觉编码:支持单图、多相机、多时序tokenization。默认用Cosmos-Reason的ViT,高效压缩多相机输入(triplane或Flex等进一步降token)。关键是减少token数,保证实时。
- 推理骨干:Cosmos-Reason(为Physical AI预训练的VLM)。输入多相机+历史ego-motion+可选文本(导航指令),输出CoC-style推理痕迹。
- 动作解码:扩散-based trajectory decoder(flow matching)。用离散token训练(便于VLM统一序列),推理时用连续专家解码生成平滑、可执行轨迹(unicycle动力学建模,加速度+曲率)。推理条件动作生成,实现对齐。
- 整体流程:多模态token序列 → Cosmos-Reason生成推理 + 离散轨迹token → 动作专家转连续轨迹。
结构亮点是解耦却协作:VLM负责高层次因果理解,扩散专家负责低层次物理可行性。
实现细节:混合数据 + 多阶段训练
实现基于Cosmos系列,强调实用。
- CoC数据集:混合人工+自动标注。人工两阶段(关键组件 + 决策 + 合成CoC),规则过滤无效数据;自动用大模型+元动作检测生成大规模数据。QA严格,确保因果正确。
- 训练三阶段:
- 动作模态注入:在VLM上加离散轨迹token,SFT学习联合预测推理+动作。引入动作专家(flow matching),训练时VLM输出离散,专家解码连续。
- 激发推理:用CoC数据集SFT,让模型学会生成结构化因果痕迹。
- RL后训练(重点):用GRPO优化。奖励三部分:
- 推理质量:大推理模型(LRM)打分,评估行为一致性和因果正确性。
- 推理-动作一致性:解析推理决策 vs. 实际轨迹元动作,匹配给正奖励。
- 轨迹质量:L2模仿 + 碰撞惩罚 + jerk平滑。
数据精选:优先模型内部偏好与外部奖励不一致的样本,提高效率。
RL让模型从“模仿”转向“自我优化”,显著提升长尾一致性和安全性。推理时99ms端到端,实时可用。
实验部分:长尾显著提升
实验覆盖开环、闭环和实车。
- 开环:CoC数据集上,AR1比纯轨迹基线minADE改善明显,尤其挑战场景。Scaling(0.5B到7B)持续提升。
- 闭环(AlpaSim):碰撞率降35%,规划准确率提12%。RL后推理质量+45%,一致性+37%。
- 实车:城市道路测试,成功部署,延迟低。
- 消融:CoC推理、RL对齐、视觉tokenization各有贡献。推理在交叉口让行等场景体现明显优势。
结果显示:推理不是锦上添花,而是长尾性能的关键。
小结和感想
Alpamayo-R1的框架是用结构化CoC把推理和VLA动作预测桥接起来,三阶段训练(注入动作 → SFT推理 → RL对齐)让模型既懂“为什么”,又能“做得对”。VLA让视觉语言动作统一,RL则提供闭环反馈,解决纯模仿的短板。这条路很务实,向L4迈进了一步。当然,计算成本和数据集构建还有优化空间,但整体思路值得参考。