Abstract: This blog post provides a overview of the 2021 ICLR paper “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” by Alexey Dosovitskiy and team at Google Brain, adapting the Transformer to vision by treating images as sequences of patches. It covers the principles of patch embedding and global attention; the encoder-only structure with variants like ViT-Base/Large/Huge; implementation aspects including pre-training on large datasets and fine-tuning; and key experimental insights on scaling effects, where large-scale pre-training outperforms CNN inductive biases on benchmarks like ImageNet, plus appendix details on hyperparameters and visualizations.
这篇论文把NLP里的Transformer直接搬到图像识别上,证明了纯注意力模型在大规模数据下能碾压CNN。读起来挺有启发,尤其是它强调“规模大于归纳偏置”的想法。现在大模型时代,这思路更显先见。
背景和动机
在NLP里,Transformer已经是标配:预训练大模型,再微调小任务,性能飙升。但视觉领域还是CNN的天下,从LeNet到ResNet,大家都依赖卷积的局部性和平移不变性。作者们好奇:Transformer这么牛,为什么不直接用在图像上?之前有人试过,但要么和CNN混用(比如加注意力层),要么用特殊注意力(局部或轴向),效率低,没大规模化。
动机简单:图像也能看成序列。作者最小改动地应用标准Transformer——把图像切成小块(patch),像处理词一样喂给模型。关键洞察:Transformer没CNN的内置偏置(inductive bias,如局部性),小数据集上弱,但大数据上强。论文验证:用14M-300M图像预训,ViT在ImageNet等基准上赶超SOTA CNN,还省计算。
核心原理:图像序列化和注意力处理
ViT的原理是把2D图像转1D序列,让Transformer捕捉全局依赖。
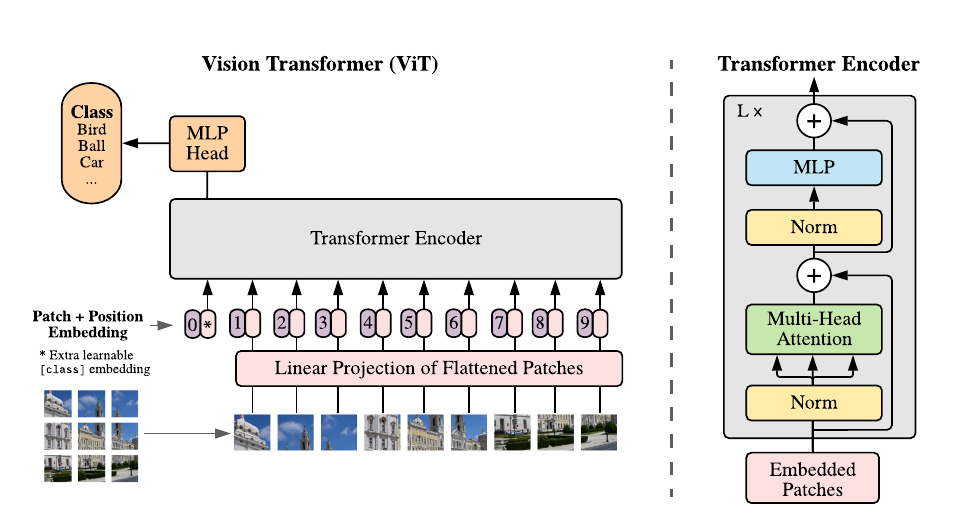
- 图像分块(Patch Extraction):输入图像($H × W × C$)切成$P × P$小块(默认16×16),展平每个块成向量,再线性投影到D维嵌入(像NLP的词嵌入)。加位置编码(学到的或固定的),防止模型忽略空间信息。序列长度$N = (H×W)/P^2$,加个[class] token汇总全局表示(像BERT的CLS)。
- 注意力机制:全用Transformer的自注意力。每个位置attend所有位置,捕捉远距离关系(CNN难)。多头注意力(Multi-Head)并行多视角,公式同原Transformer:Q、K、V投影后点积softmax。MLP层加非线性。没卷积,纯前馈。
为什么有效?注意力全局,数据大时学到CNN的偏置(locality等)。小数据弱,但预训放大优势。
模型结构:简单堆叠的Transformer编码器
ViT结构就是Transformer编码器堆叠(L层,默认12-24),没解码器,因为是分类任务。
- 输入层:图像分块 + 线性投影 + 位置编码 + [class] token。
- Transformer块:每块两个子模块:
- 多头自注意力(MSA):LN后注意力,残差连接。
- 前馈网络(MLP):LN后两层全连接(GELU激活),残差。
公式:$z’ = MSA(LN(z)) + z$,$z = MLP(LN(z’)) + z’$。
- 输出:最后一层[class] token过MLP头,softmax分类。
变体:ViT-Base (L=12, D=768, heads=12),ViT-Large (L=24, D=1024, heads=16),ViT-Huge (L=32, D=1280, heads=16)。参数从86M到632M,类似BERT。
结构简洁,没CNN层,全注意力+MLP。
实现细节:预训和微调的工程优化
实现上,作者用最小改动:基于标准Transformer库。
- 预训练:监督分类,大数据集如JFT-300M(300M图像,18k类)。AdamW优化,warmup+cosine衰减。输入224×224,patch 16×16。混合精度加速。
- 微调:换头,调分辨率(用2D插值位置编码)。加Mixup、CutMix正则。分辨率高时,用positional embedding调整。
- 计算效率:序列长短(196 for 224/16),比像素级注意力省(O(N²) vs O(HW²))。TPU上训JFT需几天。
代码开源(vision_transformer),易上手。
实验部分:规模效应和比较
第4节实验是论文亮点,证明ViT在大规模预训下牛。关键点:
- 预训数据集影响:小数据集(ImageNet 1M)上,ViT弱于ResNet(e.g., ViT-L/16: 76.5% vs BiT-L: 80.0%)。但用ImageNet-21k (14M),ViT追平;JFT-300M (300M),ViT超SOTA(ViT-L/16: 87.1% top-1 on ImageNet)。结论:规模>偏置。
- 缩放性能:模型大、数据多、计算多,性能线性涨(log-log plot)。ViT-H/14在JFT上88.55% ImageNet,省资源(比Noisy Student少4x FLOPs)。
- 转移学习:微调到CIFAR-100 (94.55%)、Oxford Flowers等,超CNN。VTAB 19任务套件77.63%,自然/结构/遥感子集都强。
- 消融:小patch (e.g., 14×14)更好(细粒度)。位置编码学的好于sin/cos。混合架构(前CNN后Transformer)在小数据好,但大数据ViT纯种胜。
附录:一些实用细节
附录有超参表、变体实验。重要点:
- 超参数:batch 4096,lr 0.3,weight decay 0.1。DropPath率0.1防过拟。
- 分辨率调整:微调时上采样位置编码,用bicubic插值。
- 自监督预训:试了,但监督更好(或许数据不够)。
- 注意力图可视:低层局部,高层全局,像CNN的层次。
这些细节帮实现,避免坑。
感想
ViT的框架是图像序列化+纯Transformer,思想是靠数据规模克服偏置缺失。结构简单,实现易扩展,现在扩散到检测、分割。ViT衍生出Swin、DETR等,但原论文的纯净思路值得回味。