Abstract: This blog post provides an overview of the 2021 paper “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows” by Ze Liu and colleagues at Microsoft Research Asia, proposing a versatile Transformer backbone for vision tasks by addressing scale variations and high-resolution challenges. It details the core principles of hierarchical representations and shifted-window attention for linear complexity; the multi-stage structure with patch merging and alternating W-MSA/SW-MSA blocks; implementation aspects like relative position bias and efficient cyclic shifts; and key experimental findings on superior performance in classification (ImageNet), detection (COCO), and segmentation (ADE20K), plus appendix insights on variants and ablation studies confirming the shifted-window efficacy.
这篇论文是ViT之后的自然延伸,它解决了纯Transformer在视觉任务上的痛点,比如高分辨率图像的计算瓶颈。读下来,思路很接地气:借NLP的Transformer,但加了视觉专属的层次和局部注意力。为什么牛?因为它不只在分类上准,还能当通用backbone,轻松适配检测和分割。
背景和动机
Transformer在NLP里大杀四方,但视觉领域还是CNN主宰。从ViT开始,有人试着把Transformer搬过来,但问题明显:视觉实体尺度多变(小物体大背景),图像分辨率高(像素比词多),全局注意力导致复杂度O(n²),高分辨率时吃不消。ViT产生单分辨率特征图,不适合检测/分割那种dense任务。
论文想做个通用视觉backbone,像ResNet一样多面手。动机:设计层次Transformer,类似CNN的金字塔特征;用局部窗口注意力降复杂度到线性(O(n))。Swin(Shifted Windows)的名字就点出关键:移位窗口连接局部,建跨窗联系。结果?能在ImageNet分类、COCO检测、ADE20K分割上超SOTA,还兼容all-MLP架构。
核心原理:层次表示 + 移位窗口注意力
Swin的核心是适应视觉的两个创新:层次结构和移位窗口。
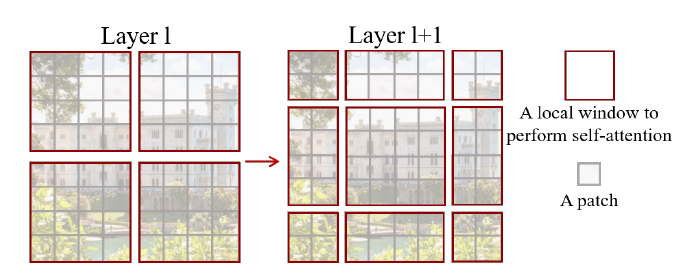
- 层次表示:不像ViT固定patch大小,Swin从小patch起步,逐层合并邻域patch,形成金字塔特征图(类似FPN)。输入图像切成4×4 patch(灰块),深层合并成更大尺度。这解决尺度变异,方便dense任务(如检测用多尺度融合)。
- 移位窗口注意力:全局注意力太贵,Swin限自注意力在非重叠局部窗口内(红块),窗口数固定,复杂度线性于图像大小。关键是“移位”:连续层间窗口移位(下图),桥接前层窗口,建全局联系。为什么移位?直接全局O(n²)不行,滑动窗虽局部但硬件慢(不同query不同key)。移位让query共享key,高效。
加相对位置偏置(relative position bias):注意力公式加B矩阵,编码相对位置(表4证明有效)。这引入翻译不变性,补Transformer的inductive bias缺失。
原理上,Swin平衡全局(注意力)和局部(窗口),线性复杂度让高分辨率可行。
模型结构:Swin Transformer块的堆叠
结构是Transformer编码器的层次变体,分4阶段(stages),每阶段降分辨率。
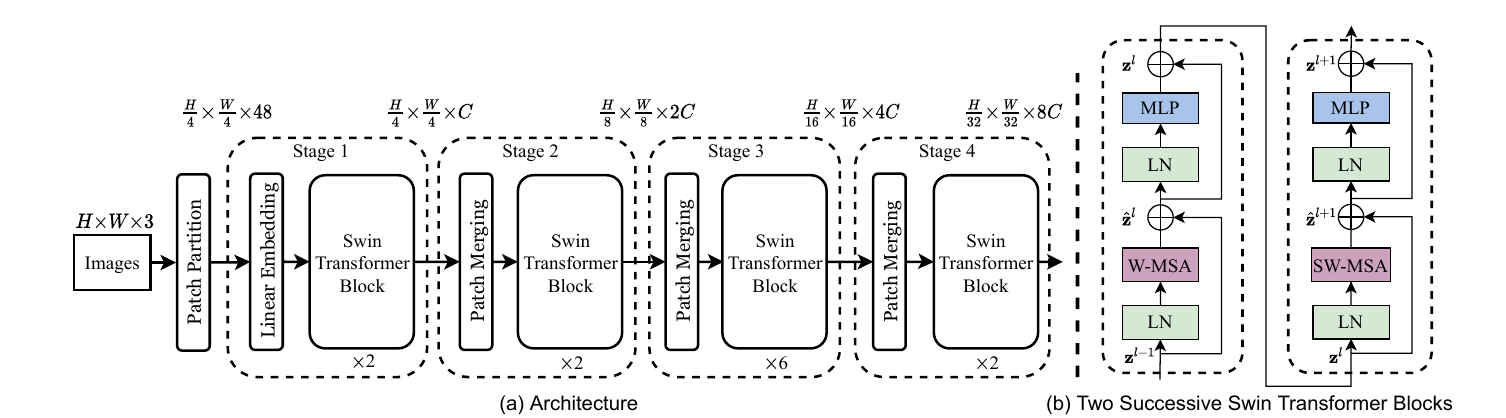
- 输入处理:图像切成4×4 patch,线性投影到C维嵌入(C=96 for Tiny)。加位置编码(相对偏置在注意力里处理)。
- Swin Transformer块:每块两个子模块:
- Window Multi-head Self-Attention (W-MSA) 或 Shifted W-MSA (SW-MSA):标准MSA,但限窗口。移位层用cyclic shift实现(高效,避免padding)。
- MLP:两层全连接,GELU激活。
残差+LayerNorm连接。连续块:W-MSA + SW-MSA交替(移位建连)。
- 阶段过渡:Patch Merging层合并2×2邻域,降分辨率2×,通道翻倍(concat+线性)。
变体:Swin-T (Tiny, C=96, 层数{2,2,6,2}),Swin-S/B/L更大。参数28M-197M,FLOPs4.5G-34.5G。整体像ResNet,但注意力替换卷积。
实现细节:简单高效的工程实践
实现上,基于PyTorch,代码开源。超参:头数d=32,MLP扩展α=4。训练用AdamW,cosine衰减,aug如RandAug/Mixup。ImageNet-1K训300epoch,batch 1024;大分辨率微调。预训ImageNet-22K提升。效率:移位窗比滑动窗快3-4×(表5),cyclic实现优于padding。
附录有详细arch和设置:分类用GAP+线性头;检测用3× schedule;分割用UperNet,160k iter。stochastic depth率0.2-0.5防过拟。
实验部分:性能和消融
第4节实验在ImageNet-1K分类、COCO检测、ADE20K分割上验证。Swin超ViT/DeiT和ResNeXt,延迟类似。
- 分类:Swin-T 81.3% top-1(ViT-S 79.9%),Swin-L 87.3%(预训22K)。大输入如384²提升到82.2%(表8,附录)。
- 检测:Cascade Mask R-CNN上,Swin-T 50.4 box AP / 43.7 mask AP(ResNet-50 46.3/40.1)。系统级HTC++,Swin-L 58.7/51.1 AP(超Copy-paste +2.7/2.6)。
- 分割:UperNet上,Swin-T 46.1 mIoU(DeiT-S 44.0),Swin-L 53.5(超SETR +3.2)。
消融移位窗+1.1% acc / +2.8 AP / +2.8 mIoU。相对偏置+1.2% acc等。不同注意力方法:移位比Performer快,准+2.3%(表6)。附录更多exp:不同输入大小,acc随分辨率涨但速度降;Swin-Mixer验证通用性(81.3% vs MLP-Mixer 76.4%)。
感想
Swin的框架是层次+移位窗,思想是高效全局建模,补视觉短板。它影响了Swin V2、视频Transformer等。