Abstract: This blog provides an accessible explanation of the 2020 paper “Lift, Splat, Shoot” , focusing on an end-to-end architecture for generating bird’s-eye-view (BEV) representations from multi-camera images in autonomous driving. It highlights the framework’s three core steps: “Lift,” which implicitly unprojects 2D images into 3D frustums using latent depth distributions; “Splat,” which fuses these into a rasterized BEV grid via pillar pooling; and “Shoot,” which enables interpretable motion planning by evaluating template trajectories on a learned cost map.
论文的核心是解决多相机输入怎么直接融合成鸟瞰图(BEV)表示的问题,不依赖激光雷达,只靠图像就能得到3D感知。
在自动驾驶里,感知系统不是简单地从单张照片里抠出物体,而是要处理一堆相机拍的图像,把它们融合成一个统一的“上帝视角”——鸟瞰图。论文提出的“LSS”框架(Lift-Splat-Shoot的缩写),巧妙地用隐式反投影把2D图像抬升到3D空间,再扁平化成BEV。这思路不只适用于自驾车,还能启发其他多视图任务。
背景
想象一下,你开着车,车上装了6个相机,分别拍前后左右。每个相机都有自己的视角(坐标系),但规划系统需要一个统一的鸟瞰图:从上往下看,整个场景的语义表示,比如哪里是车、哪里是路、哪里能走。这不是简单的图像分割,因为输入是多视图的,输出要换坐标系(从相机局部到 ego-car 全局)。
传统方法有啥痛点?比如,先在每张图像上跑2D检测,再根据相机内外参(intrinsics和extrinsics)转到3D空间进行匹配和融合。这听起来直观,但有三个问题:
- 没法端到端学习:检测和融合是分开的,模型学不到怎么最好地融合多相机信息。
- 无法准确的估计深度和融合:2D检测推3D检测,因为问题是“变态”的,深度常常估计不准确,一般称这种3D框为“伪3D”或“2.5D”。且由于深度估计不准,同一个物体在不同相机里的位置可能差很多,无法准确地匹配和融合。
- 对称性缺失:论文强调了三个关键对称性——平移等变(图像移位,输出也移)、排列不变(相机顺序不影响输出)、ego-frame 等距等变(旋转/平移ego坐标,输出跟着变)。简单方法能继承前两个,但第三个往往丢了。
本论文的方法,既保持这些对称性,又端到端可微分。核心思路:不直接预测深度,而是隐式地“抬升”图像到3D,再“溅射”到BEV平面。
核心框架:Lift-Splat-Shoot 的三部曲
论文的方法部分是重头戏,分成三个步骤:Lift(抬升)、Splat(溅射)和Shoot(射击)。
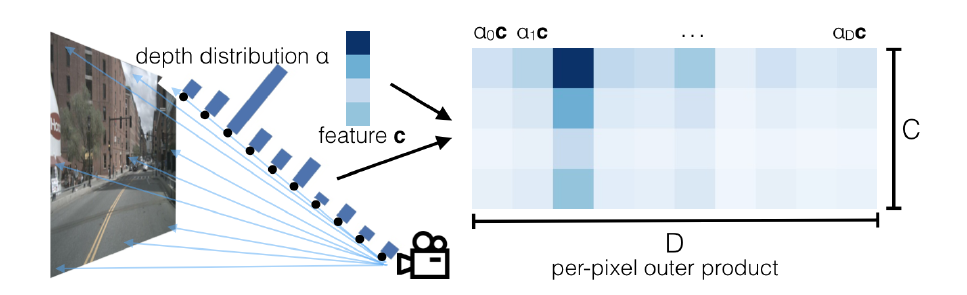
1. Lift:从2D图像抬升到3D frustum(视锥体)
第一步是处理每张图像独立,把它从平面“抬升”到3D空间。为什么独立?因为这样保持了排列不变性,不依赖相机顺序。
关键挑战:单目图像深度是模糊的(一个像素可能对应远处或近处的物体)。论文不直接回归深度,而是为每个像素预测一个深度分布(categorical distribution)。具体来说:
- 输入一张图像 X(3×H×W),用CNN(论文用EfficientNet-B0预训练骨干)提取特征。
- 对于每个像素 p(坐标 h,w),网络预测两个东西:
- 一个上下文向量 $c ∈ R^C$(C是通道数,代表语义特征)。
- 一个深度分布 $α ∈ △^{D-1}$(softmax输出,D是离散深度 bin 的数量,比如从4m到45m,每1m一个bin)。
- 然后,为像素 p 生成一个“射线”上的点云:每个深度 $d ∈ D$,对应一个点 (h,w,d),特征是 $c_d = α_d * c$(外积)。
这就形成了一个 frustum 形状的点云(视锥体,像个喇叭,从相机扩散出去)。为什么这样设计?
- 如果 α 是 one-hot(只在某个 d 非零),就退化成伪激光雷达(pseudolidar),深度确定。
- 如果 α 均匀,就均匀分布特征,像OFT方法。
- 模型能学到深度不确定性,比如模糊物体均匀撒特征。
这个步骤隐式反投影:不用显式深度图,而是用分布编码所有可能深度。结果是每个相机一个大点云(D×H×W点),共享3D坐标系。
2. Splat:溅射到BEV平面,形成栅格表示
现在有n个frustum点云,怎么融合?用“Splat”:根据内外参,把所有点“溅射”到参考平面(通常是地面,BEV坐标)。
- BEV网格是 X × Y(论文用-50m到50m,每0.5m一格,200×200)。
- 每个点根据内外参投影到BEV平面,落到“柱子”(pillar)里——pillar是无限高的voxel(体素),像PointPillars里的设计。
- 用sum pooling聚合每个pillar里的特征(不是max pooling,因为sum更可微)。
为了效率,论文用“cumsum trick”:先排序点云,按pillar id累加特征,再在边界减法求sum。这避免了padding,加速2倍(autograd友好)。他们管这个层叫“Frustum Pooling”,独立于相机数n,输出固定C × X × Y tensor。
这个步骤保持了ego-frame等距等变:旋转ego坐标,所有点跟着转,输出也转。融合是数据驱动的,模型学到怎么处理重叠视图或噪声。
3. Shoot:射击轨迹,实现端到端规划
前两步给出BEV表示 $y ∈ R^{C × X × Y}$,可以接CNN做分割。但论文更野心:用它做规划!
规划 Framing成分类:预测K个模板轨迹的分布(模板从专家轨迹K-Means得来,论文用K=1000,5秒轨迹,每0.25s采样)。
- 模型输出cost map $c_o(x,y)$(BEV上的成本函数)。
- 轨迹概率用Boltzmann形式:$p(τ_i | o) = exp(-sum_{x,y in τ_i} c_o(x,y)) / Z$。
- 训练用交叉熵,标签是ground-truth轨迹最近邻模板。
- 测试时,“射击”模板到cost map,选最低成本的执行。
这比NMP的hard-margin loss优雅,因为cost map可解释(可视化高成本区如障碍)。端到端:从图像到规划,反向传播优化整个链条。
实现细节
架构上,两个骨干:
- 图像端:EfficientNet-B0提取特征,抬升frustum。
- BEV端:ResNet-like CNN处理splat后tensor(14.3M参数)。
- 输入图像缩到128×352,BEV 200×200,深度D=41(4-45m)。
效率关键:frustum pooling用cumsum trick,Titan V上35Hz。训练用Adam,300k步。
论文强调模型对相机rig鲁棒:训练时随机掉相机或加噪声,能学到融合策略,甚至零样本转移到新rig(nuScenes训,Lyft测)。
小结
LSS的魅力在于“隐式”:不强求精确深度,而是用分布和溅射让模型自己学3D表示。这保持了对称性,又端到端,适合真实自驾场景(相机抖动、丢失常见)。比起依赖lidar的方案,便宜可扩展。缺点?单帧输入,未来加时序视频能更好。