Abstract: This blog offers an overview of the 2021 paper “BEVDet” , introducing a modular paradigm for unified 3D object detection in bird’s-eye-view (BEV) space from multi-camera inputs in autonomous driving. It details the four-stage pipeline: an image-view encoder for feature extraction; a view transformer (leveraging LSS) for implicit depth-based projection to BEV; a BEV encoder for spatial refinement; and a task head for predictions.
背景和动机
在自动驾驶里,感知系统需要从多个相机捕捉的图像中理解周围环境,比如检测物体位置、尺寸、方向和速度,然后交给规划模块决策。传统方法在图像视图(image-view)中处理,先在每张图上做2D检测,再转到3D空间。问题是没法统一处理多视图融合,计算开销大;而且3D检测和BEV语义分割用不同的范式,导致多任务学习不方便。
论文从2D检测的范式中得到启发,比如Faster R-CNN模块化、可扩展的设计。而且,BEV语义分割已经有一些成功的范式,例如LSS,为什么不扩展到3D物体检测呢?论文的核心动机就是提出了这个“BEVDet”模块化范式。
BEVDet的核心框架:四个模块的流水线
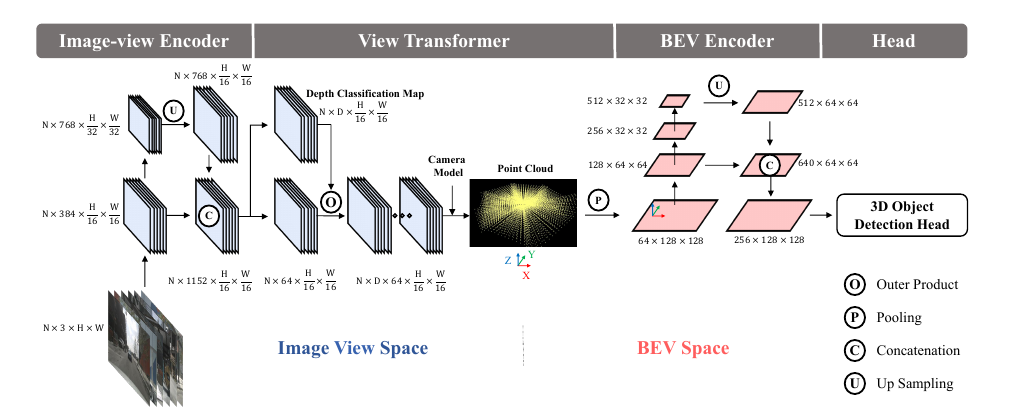
BEVDet的设计很模块化,像搭积木一样分成四个部分:图像视图编码器(image-view encoder)、视图变换器(view transformer)、BEV编码器(BEV encoder)和任务特定头(task-specific head)。每个模块有明确分工,从输入的多张图像一步步推到BEV中的3D预测。整个流程是端到端的。
- 图像视图编码器:负责从每张相机图像中提取特征。论文用Swin Transformer作为骨干网络(backbone),再加一个颈部(neck)来融合多尺度特征。为什么Swin?因为它在图像分类和检测上表现好,注意力机制能捕捉长距离依赖。输入是N张图像(N是相机数,比如nuScenes的6个),输出是图像视图下的特征图。简单说,就是把原始RGB图像转成高维特征,准备好下一步变换。也可以使用Resnet作为这一步的backbone。
- 视图变换器:把图像视图特征“抬升”到BEV空间。论文直接借用了Lift-Splat-Shoot(LSS)方法:先为每个像素预测深度分布(不是精确深度,而是分类分布),生成一个伪点云;然后根据相机内外参,把这些点云“溅射”(splat)到BEV网格上,形成栅格化表示。LSS的好处是隐式处理深度不确定性,不依赖激光雷达。这个变换是像素级的,解耦了前后模块的数据增强——这点后面会说。
- BEV编码器:论文用ResNet结构的CNN来编码,添加上采样和池化层来调整分辨率。为什么需要这个?因为原始BEV特征可能还不够鲁棒,这里能捕捉BEV空间的上下文,比如物体的相对位置和速度。
- 任务特定头:针对3D物体检测预测目标值,包括类别、位置、尺寸、方向和速度。论文用CenterPoint的head,它基于中心点预测,适合BEV的栅格表示。为什么CenterPoint?因为它在LiDAR-based检测上证明有效,能直接在BEV上操作。
整个框架如下图所示,从图像空间到BEV空间的转换很顺畅。论文没发明新模块,全是复用现有技术。
方法和实现的关键点:数据增强与过拟合处理
论文还讨论了实现中的挑战,特别是过拟合。起初,论文用类似FCOS3D的参数设置训练,结果模型在BEV空间过拟合严重。图像视图数据是N倍的(每个场景多相机),但BEV部分数据少,容量又强。
原因如下:
在训练batch(一批数据)里,图像视图编码器(image-view encoder)每次要处理N张图像的特征提取。所以,对于一个场景(scene),它“看到”的数据是N倍的——相当于每个场景贡献了6份图像数据,让这个模块学得特别丰富。简单说:图像端数据多,训练机会足,模型不容易饿肚子。
视图变换器(view transformer,用LSS方法)把N张图像的特征“抬升”并融合成一张BEV特征图。所以,BEV编码器(BEV encoder)和后面的检测头(head)在每个batch里,只处理1份BEV数据(一个场景的鸟瞰表示),而不是N份。结果:BEV端的“有效训练样本”只有图像端的1/N。数据少,模型就容易记住训练集的噪声或特定模式,而不是学到泛化能力。
BEV部分用ResNet之类的强大骨干,参数多,容量(模型的表达能力 model capacity)大,拟合复杂模式的能力强(比如捕捉物体位置、速度的细微变化)。但高容量+低数据=灾难!模型太“聪明”了,会把有限的BEV数据过分拟合(比如死记硬背每个场景的像素级细节),一到新数据就傻眼。
解决方案是分空间数据增强:
- 图像视图增强:借鉴LSS,添加旋转、缩放、随机裁剪等操作,提升图像编码器的泛化。但这对BEV部分影响小,因为视图变换解耦了它们。
- BEV视图增强:这是创新点,借鉴LiDAR方法,在BEV空间加翻转、缩放、旋转。为什么有效?因为BEV是规划友好的空间,这些操作直接正则化了位置、方向和速度的预测,避免模型死记硬背。
实现细节上,输入图像分辨率可调(从704×256到1408×512),BEV网格是128×128或更高。计算量控制在几百GFLOPs,推理速度快。论文提到,BEVDet对平移、方向和速度感知特别强,因为BEV显式编码了这些属性。