Abstract: This blog post offers an overview of the 2022 paper “BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers” by Zhiqi Li and colleagues at Shanghai AI Laboratory, introducing a Transformer-based encoder for unified BEV features in autonomous driving without explicit depth reliance. It explains the principles of grid-shaped BEV queries with spatial cross-attention for multi-view aggregation and temporal self-attention for recursive history fusion; the CNN-plus-encoder structure with task heads for detection and segmentation; implementation details like deformable sampling and ego alignment; and experimental highlights on nuScenes, including state-of-the-art NDS (56.9%), improved velocity estimation, and occlusion handling.
这篇论文解决的是自动驾驶感知的痛点:怎么从多相机2D图像生成统一的鸟瞰图(BEV),支持检测和地图分割。论文巧妙结合了Transformer和时空信息,不靠深度估计,避免了累积误差,还能处理时序数据。为什么实用?因为BEV是规划的桥梁,能统一多任务。
背景和动机
自动驾驶感知离不开3D理解,比如检测物体或分割地图。相机便宜,长距识别强,却难从2D转3D。传统单目方法独立处理每视图,融合差;BEV方法流行,但多靠深度估计(如LSS),易出错,影响检测准度。论文认为Transformer的注意力能动态聚合特征,不用硬深度先验,就能学BEV。
另一个点是时序:人类开车靠视频推测速度和遮挡,但多相机检测少用时间信息。简单栈帧费算力,还干扰。作者想用BEV桥接时空,像RNN隐状态,递归传历史信息。动机:设计不靠深度的BEV生成器,支持多任务,高效用时空数据,提升低可见度下的召回和速度估计。
核心原理:网格查询 + 时空注意力
BEVFormer的核心是时空Transformer,用网格BEV查询(queries)动态查空间/时间,聚合特征。见下图。
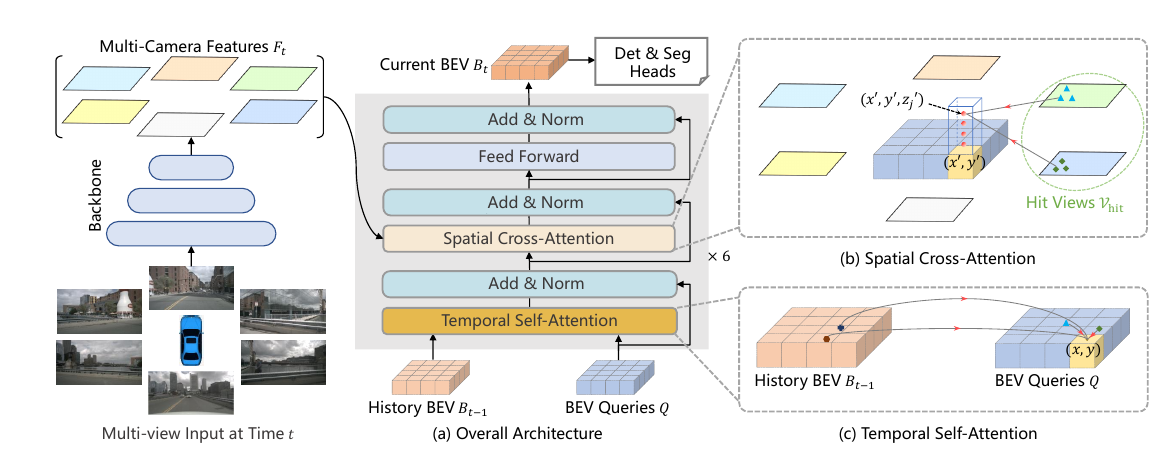
- 网格BEV查询:预定义网格状查询(像DETR的对象查询),每个代表BEV一格。查询不靠深度,靠注意力灵活学表示。
- 空间交叉注意力:每个查询从感兴趣区域(ROI)提取多相机特征。ROI用相机内外参投影3D点到2D视图,采样特征点。变形注意力(Deformable Attention)高效,只采样关键点,避免全局算。
- 时间自注意力:递归融合历史BEV。当前查询attend前帧BEV(对齐ego运动),传时序线索。益处:估速准,识遮挡物,低开销。
原理上,BEVFormer避深度敏感,用注意力学时空关联。BEV统一表示,多任务友好。
模型结构:时空Transformer编码器
结构是CNN backbone + BEVFormer编码器 + 任务头。输入多相机图像(可选多帧)。
- CNN Backbone:ResNet或VoVNet提取多视图特征,加位置编码。
- BEVFormer编码器:L=6层,每层时空模块:
- 时间自注意力:查询attend历史BEV(初始空)。
- 空间交叉注意力:查询采样多视图ROI特征。
- FFN:前馈网络,加残差+Norm。
- 任务头:BEV输出接Deformable DETR头检测,或mask解码器分割。
整体递归:当前BEV存历史,下帧用。像视频Transformer,但BEV桥接高效。
实现细节
实现基于PyTorch,超参:BEV 200×100 (0.5m分辨),查询网格50×30。采样点K=4,注意力头8。训练:AdamW,nuScenes 24epoch,aug如翻转。时间融合用前6关键帧,ego对齐。扩展:加占用头或规划。
细节上,ROI投影用内外参,采样用双线性。历史BEV存4-6帧,推理实时。
实验部分
实验在nuScenes上测。BEVFormer-ResNet101在test集NDS 56.9%(感知综合分),比之前SOTA高9点,和LiDAR基线平齐。检测mAP 45.1%,速度估mAVE 0.409m/s低。时序益处:低可见(夜/雨)召回高10%+,速度准因历史。消融:时空模块各+3-5 NDS。地图分割mIoU 62.0%,超之前。
这些结果显示BEVFormer在相机感知上追LiDAR,时空设计实用。
感想
读BEVFormer,觉得它桥接时空的思路优雅,简化多相机感知,它影响了BEVFormer v2等。