Abstract: TThis blog post offers an overview of the 2022 paper “BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework” by Tingting Liang and colleagues, introducing a disentangled fusion approach where camera and LiDAR streams independently extract features into a shared BEV space before dynamic fusion. It explains the principles of modality-independent processing to handle LiDAR malfunctions; the camera stream based on adapted Lift-Splat-Shoot with Dual-Swin backbone, view projection, and BEV encoder; the LiDAR stream using popular detectors like PointPillars or CenterPoint; the lightweight dynamic fusion module with channel-spatial fusion and adaptive selection; and experimental highlights on nuScenes, demonstrating superior performance under normal (69.2% mAP) and robust settings (+15.7% to 28.9% mAP) while maintaining strong generalization.
最近读了2022年的NeurIPS论文《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》,作者是北大和阿里团队的Tingting Liang等。这篇论文不让相机依赖LiDAR,避免故障时崩溃。现实中LiDAR可能出问题,这框架能独立运行相机流,还保持高性能。现在多模态融合热门,这篇是典型代表。
背景和动机:融合的痛点和独立性需求
自动驾驶感知靠LiDAR和相机:LiDAR给精确点云,相机补纹理颜色。但早期方法分开处理,再后融合。BEV(鸟瞰图)成标准,因为车在地上跑,BEV便于规划。还有的融合方案用LiDAR点或提案查询图像特征。但作者发现隐患:这些方法依赖LiDAR输入,如果LiDAR故障(反射低、传输 glitch 或视场不全),整个系统哑火。这限制实际部署。
动机:理想融合应让每个模态独立工作,有两者更好。作者提出BEVFusion,相机流不靠LiDAR,解耦依赖。简单却有效,正常训超SOTA,鲁棒训(模拟故障)大胜。
核心原理:独立流 + BEV融合
BEVFusion原理是模态解耦:相机和LiDAR独立转BEV特征,再融合。见下图。
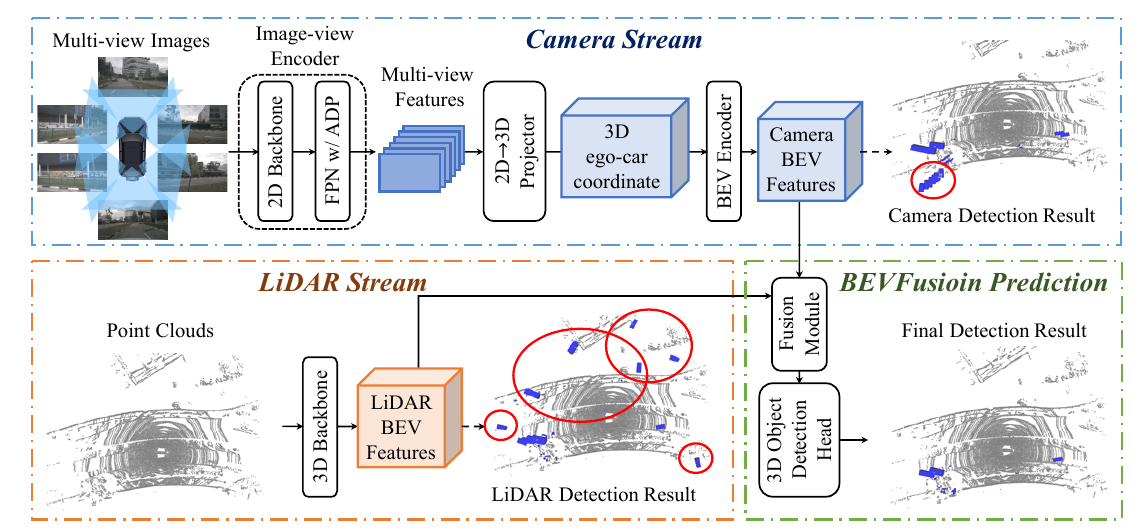
- 相机独立:不用LiDAR点查询图像,直接从多视图图像生成BEV特征。避深度缺失问题。
- BEV统一:两者特征同空间(X × Y × C),动态融合选重要信息。
- 鲁棒性:LiDAR缺时,相机流独跑;两者有时,提升准度。
原理上,避先验依赖,用数据学融合。泛化强,可插任意单模态网。
模型结构:双流 + 融合 + 头
结构直观:相机流、LiDAR流、动态融合、任务头。
- 相机流:三模块。
- Image-view Encoder:Dual-Swin-Tiny骨干 + FPN颈,提取多尺度特征。加Adaptive Module(自适应池化 + 1×1 conv)对齐上采样。
- View Projector:深度分类,转图像特征到3D ego坐标,生成伪体素V ($X × Y × Z × C$)。
- BEV Encoder:S2C操作(reshape压Z维) + 四层3x3 conv,生成$F_{camera} (X × Y × C_{camera})$。
- LiDAR流:任意网,如PointPillars、CenterPoint、TransFusion,转点云到$F_{lidar} (X × Y × C_{lidar})$。
- 动态融合:concat $F_{Camera}$和$F_{lidar}$,3×3 conv降维 + 通道注意力(GAP + FC + sigmoid),选重要特征。公式:$F_{fused} = σ(W × avg(F)) × F$。
- 检测头:BEV特征接锚基(如PointPillars)、无锚(如CenterPoint)或Transformer头(如TransFusion),预测3D框。
整体端到端,相机不挂LiDAR。
实现细节:通用设计和训练
实现基于PyTorch,超参:BEV 200×100 (0.4m分辨),相机输入1600×900。相机用LSS适配:Dual-Swin-T backbone,ADP模块。融合简单conv+SE。训练:CBGS,24epoch,AdamW。鲁棒aug:随机掉物体框内LiDAR点(prob 0.5),模拟故障。
细节上,体素化用[-54,54]x[-54,54]x[-5,3],Z=8。扩展易,换头或流。
实验部分
在nuScenes测。正常训:BEVFusion+CenterPoint mAP 68.5%、NDS 71.3%(超TransFusion 68.9%、69.4%)。用TransFusion头 mAP 69.2%。鲁棒训(掉点aug):mAP 57.3%(超基线15.7%-28.9%)。LiDAR全缺时,仍有39.2% mAP。消融:ADP +2.1% mAP;动态融合优静态。实时:23.2 FPS。
这些显示框架泛化鲁棒,实际潜力大。
一点感想
BEVFusion的框架是解耦双流+BEV融,思想实用,补融合短板。